I matematik siger den empiriske regel, at i et normalt datasæt vil stort set hvert stykke data falde inden for tre standardafvigelser Standardafvigelse Fra et statistisk synspunkt er standardafvigelsen for et datasæt et mål for størrelsen af afvigelser mellem værdier af observationer indeholdt i middelværdien. Gennemsnittet er gennemsnittet af alle numrene i sættet.
Den empiriske regel kaldes også Three Sigma-reglen eller 68-95-99.7-reglen, fordi:
- Inden for den første standardafvigelse fra gennemsnittet hviler 68% af alle data
- 95% af alle data falder inden for to standardafvigelser
- Næsten alle dataene - 99,7% - falder inden for tre standardafvigelser (de resterende .3% bruges til at tage højde for afvigelser, som findes i næsten ethvert datasæt)
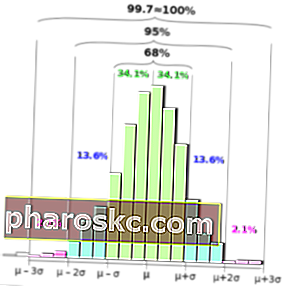
Normal fordeling
Den empiriske regel opstod, fordi den samme form for distributionskurver fortsatte med at vises igen og igen for statistikere. Den empiriske regel gælder for en normalfordeling. I en normalfordeling falder næsten alle data inden for tre standardafvigelser fra gennemsnittet. Den gennemsnitlige middelværdi er et vigtigt begreb i matematik og statistik. Generelt henviser et gennemsnit til gennemsnittet eller den mest almindelige værdi i en samling af, mode og median er alle ens.
- Gennemsnittet er gennemsnittet af alle tallene i datasættet.
- Tilstanden er det nummer, der gentages hyppigst inden for datasættet.
- Medianen er værdien af spredningen mellem det højeste og laveste tal inden for sættet.
Dette betyder, at middel-, tilstands- og medianmedianmedian er et statistisk mål, der bestemmer den midterste værdi af et datasæt, der er anført i stigende rækkefølge (dvs. fra den mindste til den største værdi). Medianen skal alle falde i midten af datasættet. Halvdelen af dataene skal være i den øverste ende af sættet og den anden halvdel nedenfor.
Bestemmelse af standardafvigelsen
Den empiriske regel er specielt nyttig til at forudsige resultater inden for et datasæt. For det første skal standardafvigelsen beregnes. Formlen er angivet nedenfor:
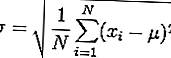
Den komplicerede formel ovenfor opdeles på følgende måde:
- Bestem gennemsnittet af datasættet, som er summen af datasættet divideret med antallet af tal.
- For hvert tal i sættet trækkes gennemsnittet og kvadrerer derefter det resulterende tal.
- Brug de firkantede værdier til at bestemme gennemsnittet for hver.
- Find kvadratroden af middelværdien beregnet i trin 3.
Det er standardafvigelsen mellem de tre primære procentdele af normalfordelingen, inden for hvilken størstedelen af dataene i sættet skal falde, eksklusive en mindre procentdel for outliers.
Brug af den empiriske regel
Som nævnt ovenfor er den empiriske regel særlig nyttig til at forudsige resultater inden for et datasæt. Statistisk set, når først standardafvigelsen er bestemt, kan datasættet let underkastes den empiriske regel, der viser, hvor datastykkerne ligger i fordelingen.
Forecasting Forecasting Forecasting refererer til den praksis at forudsige, hvad der vil ske i fremtiden ved at tage højde for begivenheder i fortiden og nutiden. Dybest set er det et beslutningsværktøj, der hjælper virksomheder med at håndtere virkningen af fremtidens usikkerhed ved at undersøge historiske data og tendenser. er mulig, fordi selv uden at kende alle dataspecifikationer, kan der foretages fremskrivninger af, hvor data falder inden for sættet, baseret på 68%, 95% og 99,7% dikter, der viser, hvor alle data skal hvile.
I de fleste tilfælde er den empiriske regel primær brug for at hjælpe med at bestemme resultater, når ikke alle data er tilgængelige. Det giver statistikere - eller dem, der studerer dataene - for at få indsigt i, hvor dataene falder, når alt er tilgængeligt. Den empiriske regel hjælper også med at teste, hvor normalt et datasæt er. Hvis dataene ikke overholder den empiriske regel, er det ikke en normalfordeling og skal beregnes i overensstemmelse hermed.
Relaterede målinger
Finance er den officielle udbyder af den globale Financial Modelling & Valuation Analyst (FMVA) ™ FMVA®-certificering Deltag i 350.600+ studerende, der arbejder for virksomheder som Amazon, JP Morgan og Ferrari-certificeringsprogram, designet til at hjælpe alle med at blive en verdensklasse finansanalytiker . For at fortsætte med at lære og fremme din karriere vil de yderligere finansressourcer nedenfor være nyttige:
- Central tendens Central tendens Central tendens er et beskrivende resume af et datasæt gennem en enkelt værdi, der afspejler centrum af datadistributionen. Sammen med variationen
- Nominelle data Nominelle data I statistikker er nominelle data (også kendt som nominel skala) en type data, der bruges til at mærke variabler uden at give nogen kvantitativ værdi
- Ikke-parametriske tests Ikke-parametriske tests I statistikker er ikke-parametriske tests metoder til statistisk analyse, der ikke kræver en fordeling for at imødekomme de krævede antagelser, der skal analyseres
- Volatilitet Volatilitet Volatilitet er et mål for frekvensen af udsving i værdien af et værdipapir over tid. Det angiver risikoniveauet forbundet med kursændringer i et værdipapir. Investorer og handlende beregner et værdipapirs volatilitet for at vurdere tidligere variationer i priserne